





本文为Fuzzing: a survey的翻译,原文作者是Jun Li, Bodong Zhao和Chao Zhang,发表在新刊Cybersecurity上。本文仅为部分翻译,图表和参考文献也只摘取了一部分,完整内容请查看原文。
关键词:漏洞检测,软件安全,模糊测试,覆盖导向的模糊测试
1 Introduction
安全漏洞是网络安全威胁的重要来源,漏洞挖掘技术可以帮助提前修复漏洞。研究者们提出了很多技术来进行漏洞挖掘,其中模糊测试(fuzzing)目前使用得最广泛。最近几年,AFL[1]等fuzzing的研究使漏洞挖掘技术取得了很大的进展。
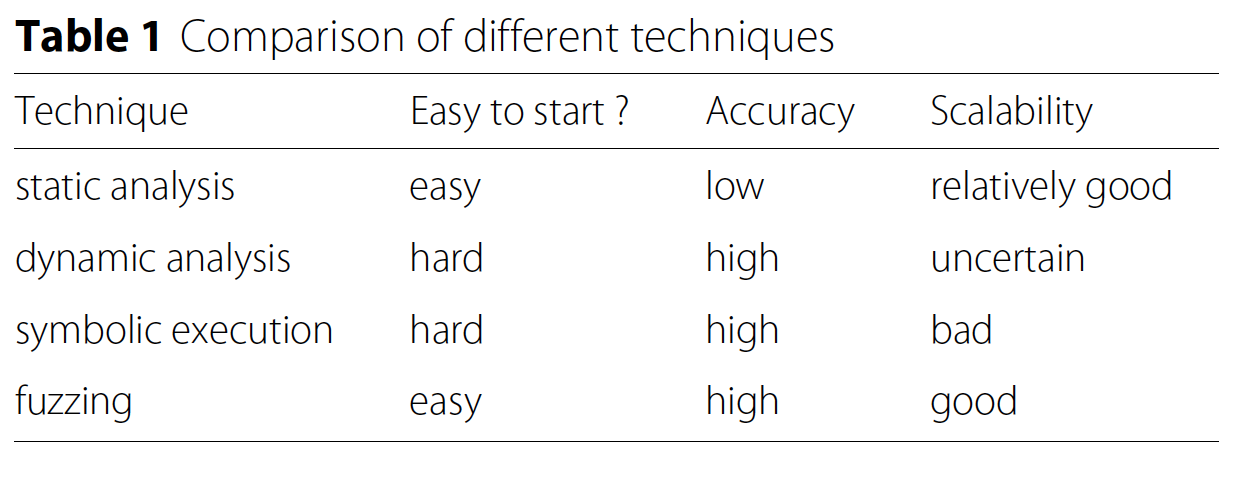
fuzzing的概念第一次在20世纪90年代提出。如图1所示,fuzzing方法利用计算机生成大量常规和非常规的测试用例,输入目标程序并监视其执行状态,试图捕获程序异常,从而发现漏洞。当捕获到程序的异常行为时,fuzzer将对应的输入保存下来,等待重现和进一步的分析。与其他漏洞检测技术相比,fuzzing的适用性和可扩展性好,准确率高,可以有源码或无源码执行。更重要的是,fuzzing仅需要很少关于目标程序的知识,并且容易部署到大规模应用程序上,因此fuzzing技术非常受欢迎,尤其是在工业界。表1比较了Fuzzing和其他漏洞检测技术的优势和劣势。
测试用例的质量直接决定着fuzzing的效果。测试用例应满足被测程序对输入格式的要求,同时也应尽量区分于最常规的输入以使被测程序崩溃。如何生成高质量的测试用例是fuzzing技术面临的最大挑战。
2 fuzzer的分类
可以按很多种方式给fuzzer分类。
根据生成器策略的不同,可以分为基于生成规则的fuzzer和基于变异的fuzzer。基于生成规则的fuzzer需要目标程序输入的相关知识。对于基于文件格式的fuzzing,通常会提供一个预定义文件格式的配置文件,fuzzer根据配置文件来生成测试用例。有了文件格式的知识,基于生成规则的fuzzer生成的测试用例就能轻松通过目标程序的验证,并且提高了测试到目标程序深层代码的可能性。但是,如果没有详细易懂的说明文档,分析文件格式就是一项艰难的工作。相比起来,基于变异的fuzzer更容易启动且适用性好,因此广泛地用于现代fuzzer中。基于变异的fuzzer需要一个初始输入集,测试用例由初始输入和fuzzing过程中新生成的测试用例变异而来。基于生成规则的fuzzer和基于变异的fuzzer的比较如表2所示。

根据对程序源码和程序分析的依赖程度,fuzzer可分为白盒、灰盒和黑盒。白盒的fuzzer假设能获得目标程序的源代码,因此能通过源码分析获取关于测试用例如何影响程序执行状态的更多信息。黑盒的fuzzer在不知道任何目标程序内部信息的情况下执行。灰盒的fuzzer虽然不能访问程序源码,但是可以通过程序分析来获取目标程序的内部信息。一些流行的fuzzer的分类如表3所示。

根据探索策略的不同,fuzzer可以分为定向fuzzing(directed fuzz)和覆盖导向的fuzzing(coverage-based fuzz)。定向fuzzing旨在生成覆盖目标代码和目标路径的测试用例,基于覆盖的fuzzing尽可能生成覆盖更多程序代码的测试用例。定向fuzzing希望对目标程序进行快速地测试,而覆盖导向的fuzzing希望进行更加彻底的测试以发现更多bug。对于这两种fuzzer,怎样提取执行路径的信息都是一个关键问题。
根据程序状态是否会影响测试用例的生成过程,fuzzer可以分为智能fuzzer(smart fuzzer)和非智能fuzzer(dumb fuzzer)。智能fuzzer根据收集到的测试用例如何影响程序执行的信息调整测试用例生成策略。对于基于变异的fuzzer,反馈信息可以用来决定测试用例的哪部分需要变异,以及如何变异。非智能fuzzer的执行速度更快,而智能fuzzer生成的测试用例质量更好,因此效率更高。
3 fuzzing面临的主要挑战
3.1 怎样变异
基于变异的生成策略被广泛用于现代fuzzer中,怎样变异以生成覆盖更多程序路径和容易触发bug的测试用例是fuzzing技术面临的一个主要挑战。基于变异的fuzzer在进行变异的时候需要回答两个问题:(1)在何处变异(2)如何变异。只有少数关键位置的变异才能改变程序执行的控制流。因此如何寻找这样的关键位置非常重要。另外,在关键位置如何变异也是一个重要问题。我们需要能引导程序进入一些“有趣”执行路径的测试用例。盲目的变异会造成测试资源的严重浪费,而好的变异策略能极大地提升fuzzing效率。
3.2 低代码覆盖率
高代码覆盖率也代表着对程序执行状态的高覆盖率,已有的工作证实了提高覆盖率也能提高发现bug的概率。然而现实情况是大多数测试用例仅仅覆盖少数相同的路径,大部分代码都无法被测试到。因此仅仅通过大规模的测试用例来提高代码覆盖率是不明智的。覆盖导向的fuzzer试图依靠程序分析技术,如程序插桩,来解决这个问题。
3.3 如何通过合法性验证
程序常常会在分析和处理输入之前验证输入的合法性,不合法的测试用例会被忽视或舍弃。常用的验证方法有magic数,magic字符串,版本号验证,校验和等。灰盒和黑盒的fuzzer难以通过盲目的生成策略产生可以通过合法性验证的输入,这会造成非常低的测试效率。因此,如何通过输入的合法性验证也是一个挑战。
4 覆盖导向的fuzzing
覆盖导向的策略被广泛用于现代fuzzer中,并且已经被证实非常有效。为了更深入和更彻底地测试程序,fuzzer应覆盖尽可能多的程序运行状态,但是由于程序行为的不确定性,并不存在一个简单好用的程序状态覆盖的标准。一个好的标准应该能在程序执行时很容易被计算出来,因此计算代码覆盖率就成了一个自然的替代方案,可以近似认为增加代码覆盖率就代表着新的程序状态。通过编译时插桩或外部插桩,很容易就能计算代码覆盖率。不过代码覆盖率不变并不代表程序状态也不变,代码覆盖只是程序运行状态覆盖的一个近似估计,使用代码覆盖率作为目标不可避免地会损失某些信息。
4.1 代码覆盖率的计算
在程序分析中,程序被认为是由一些基本块构成的。一个基本块是指只有一个入口和一个出口的代码段,基本块中的代码指令只会被顺序执行,并且每条指令仅执行一次。在测量代码覆盖率时,以基本块作为最细粒度。
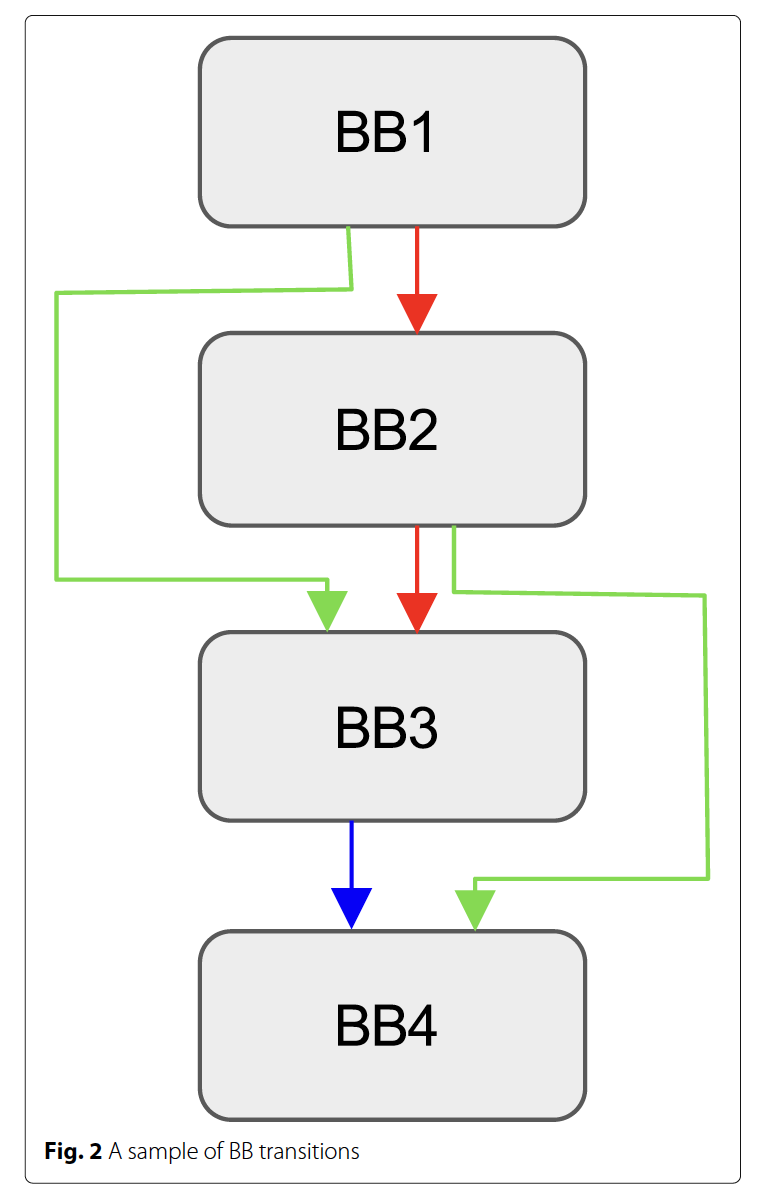
基于基本块,有两种常用的代码覆盖计算方式,仅对代码块计数和对代码块之间的转移计数。对代码块之间的转移计数方法将程序表示为图,顶点代表基本块,边代表基本块之间的转移。对代码块之间的转移计数方法记录图中的边,仅对代码块计数方法记录图中的顶点。实验显示,如果仅对代码块计数,会造成严重的信息丢失。如图2所示,如果先执行(BB1,BB2,BB3,BB4),后执行(BB1,BB2,BB4),新边(BB2,BB4)的信息就会丢失。
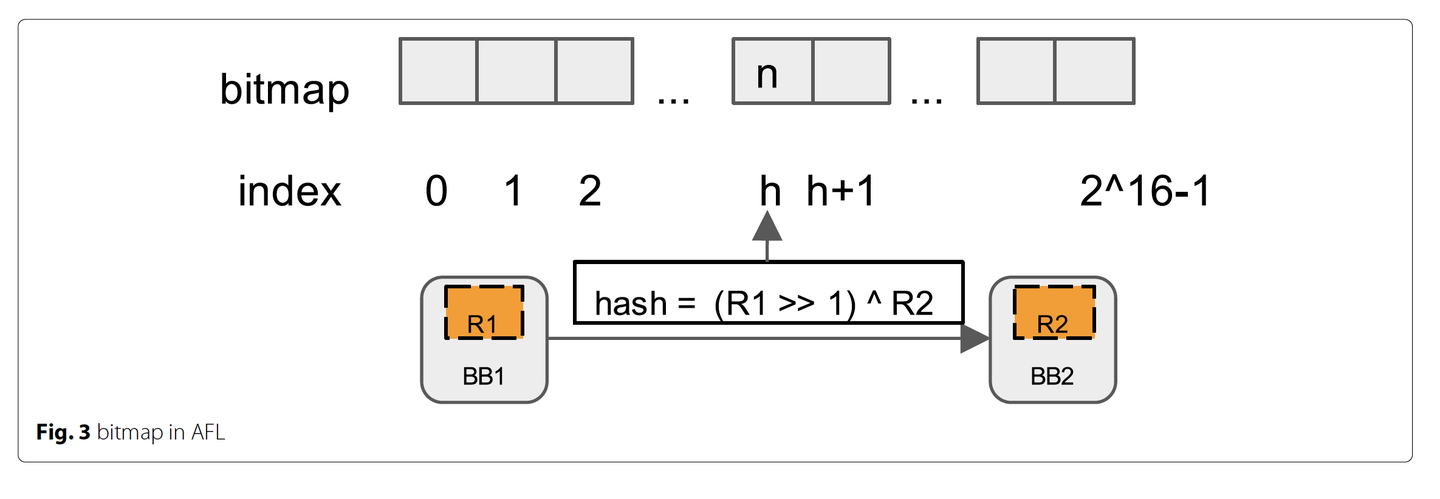
AFL[1]第一个将边覆盖度量标准用于覆盖导向的fuzzing。AFL通过轻量级的程序插桩来获得覆盖信息。根据是否能访问源码,AFL提供编译时插桩和外部插桩两种插桩模式。编译时插桩模式下,AFL在编译二进制文件时就植入检测代码,并且根据编译器不同提供gcc模式和llvm模式。外部插桩模式下,AFL使用qemu,在基本块转换为TCG块时植入检测代码。AFL使用哈希机制,用一块64KB的共享内存作为位示图来存储边覆盖信息。
4.2 覆盖导向fuzzing的执行过程
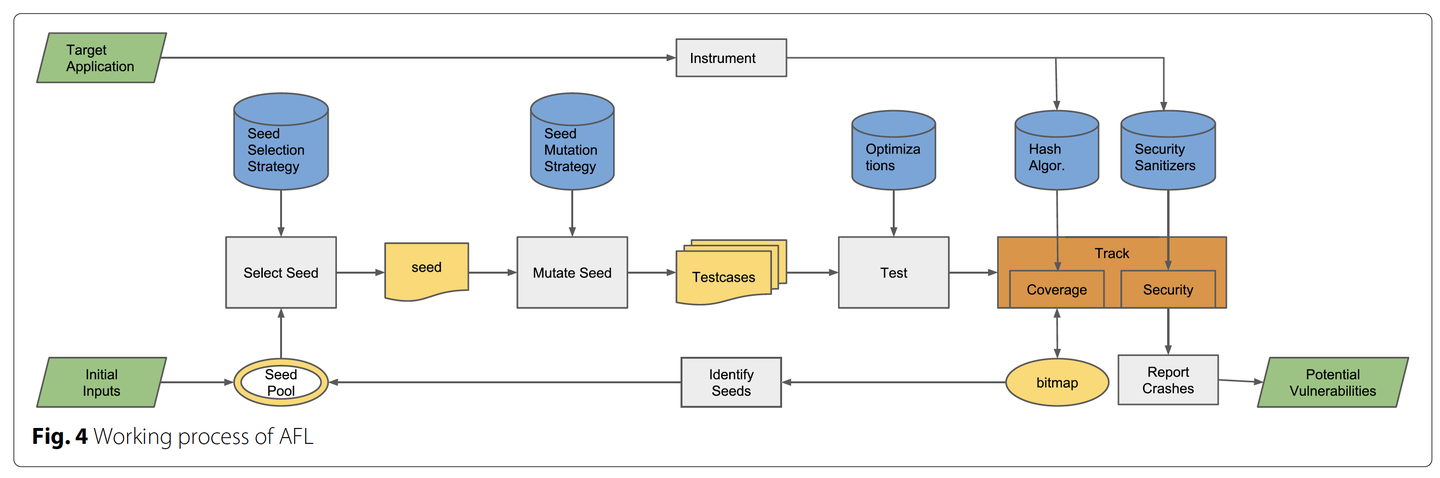
算法1显示了覆盖导向fuzzer的一般执行过程。测试从一个初始的种子输入集合开始,如果没有初始种池,fuzzer就自己构建一个。在主循环中,fuzzer重复选择“有趣”的种子进行变异生成新种子。触发了程序崩溃的输入会被保存下来,而其他“有趣”的种子会被加到种池。对于覆盖导向的fuzzing,到达新控制流边的测试用例就是“有趣”的种子。主循环在预先设定的时间停止,或者接收到中止信号时停止。
在执行测试时,fuzzer通过多种方式追踪程序执行。fuzzer主要为了提高代码覆盖率和捕捉更多违反安全规则的行为而追踪程序执行。高代码覆盖率意味着更彻底的程序状态探索,违反安全规则的行为则有利寻找bug。追踪违反安全规则的行为可以在内存错误检测器(Sanitizer)的帮助下进行,比如AddressSanitizer、ThreadSanitizer,LeakSanitizer。

AFL[1]是一个典型的覆盖导向的fuzzer,图2显示了AFL的执行过程。插桩在目标程序执行前进行。在主循环中,fuzzer根据选种策略从种池中选择一个最佳的种子,AFL偏好最快和最小的种子。根据变异策略对种子文件进行变异生成大量测试用例,AFL的策略是随机修改和对测试用例进行拼接,包括长度和步长变化的位翻转,小整数的加法、加法,已知的“有趣”整数如0、1,INT_MAX等的插入。
4.3 主要问题
a) 如何获得初始输入?
基于变异的fuzzing非常依赖于初始种池的质量,质量高的初始种池能极大提升fuzzing的效率和有效性。好的种子输入应该能在多次测试中重用,好的初始种池应满足复杂文件格式的要求。
生成初始种池的常用方法包括使用基准测试程序,从网上爬取,和使用已有的POC样例。开源应用发布时,开发者常常会提供一个根据程序的功能和特征编写的基准测试程序,基准测试程序天然能生成一个较好的种子集合。在网络上很容易下载特定格式的文件,考虑到目标程序输入的多样性,从因特网上爬取也是一种符合直觉的有效方法。对于一些常用的文件格式,还有很多开源的项目免费提供测试集。此外,使用已有的POC样例也是一个好办法。然而过量的种子输入也会造成第一轮测试的时间浪费,如何精简初始集合也是一个要考虑的问题,AFL提供一个工具用来抽取能达到相同代码覆盖的最小集合。
b) 如何生成测试用例?
VUzzer——处理magic字节
Rawat等人实现了VUzzer[2],一个集成了静态分析和动态污点分析的灰盒fuzzer。VUzzer在程序执行前通过静态分析从程序中提取立即数,magic数和其他特有字符串。在执行测试时,VUzzer利用动态污点分析技术来收集影响控制流分支的数字变量信息。在变异阶段,VUzzer对前面收集到的字段做针对性处理。实验表明,比AFL相比VUzzer能通过更少的测试用例来触发更多的程序崩溃。不足之处在于VUzzer能处理的特定字段比较有限,以及动态污点分析还是会降低fuzzer的效率。
Skyfire——通过PCSG学习合法输入样本
Wang Junjie等人提出了Skyfire[3],一个数据驱动的种子生成方案。Skyfire接收已知输入样本集合和文法,通过PCSG(Probabilistic context-sensitive grammar)自动化抽取带概率的上下文有关文法规则,并利用学习到的知识生成具有良好结构的测试样例。
利用机器学习技术
随着机器学习技术的发展,一些研究者试图使用机器学习技术来辅助测试用例的生成。微软研究院的Godefroid等人使用神经网络学习合法输入来自动生成测试用例[4]。微软的Rajpal等人使用神经网络从过去的测试结果中学习,预测应该在什么位置变异[5]。Nichols等人利用GAN生成新种子文件来重新初始化fuzzing系统[6]。
c) 如何从种池选择种子?
AFL偏好更快更小的种子以达到更快的测试速度。
Böhme等人提出了AFLFast[7],他们观察到大部分测试用例都集中在少数相同的路径上,对于一个PNG处理程序,大部分随机变异产生的测试用例都使程序进入了错误处理路径。AFLFast运行时检测路径执行的频率,使触发低频路径的种子拥有更高的优先度,并且赋予他们更高的能量(增加变异次数)。
VUzzer[2]集成了静态和动态分析技术来寻找难以到达的深层路径,优先使用到达深层路径的种子。
AFLGo[8]和QTEP[9]使用定向筛选(directed selection)策略。AFLGo定义一些了脆弱代码作为目标位置,优先选择离目标位置更近的测试用例。AFLGo的论文中指出了四种类型的脆弱代码,包括补丁代码、缺乏追踪信息的程序崩溃、静态分析工具确认的脆弱代码以及与敏感信息有关的代码段。通过合适的引导算法,AFLGo可以分配更多计算资源给可能存在漏洞的代码。QTEP利用静态分析技术检测容易出错的源代码,优先使用覆盖这些代码的种子。AFLGo和QTEP都非常依赖静态分析工具的有效性,然而当前静态分析工具的假阳性率依旧较高,难以给出准确的判断。
已知漏洞的特征也可以被用于选种。SlowFuzz[10]致力于检测算法复杂性漏洞,这种漏洞通常在计算资源消耗非常高的情况下发生,因此SlowFuzz偏好那些消耗更多CPU时间和占用多更内存的种子。然而,收集计算资源消耗信息会带来巨大的开销,降低fuzzing的效率。SlowFuzz要求资源消耗信息非常准确,为了计算CPU时间,SlowFuzz需要对执行的指令精确计数。
d) 如何高效地测试应用程序?
目标程序在fuzzing的主循环中会不断重复启动和结束,而创建和终止用户态的进程会消耗大量的CPU时间,频繁地创建和终止进程严重影响fuzzing的效率,因此有大量的研究人员致力于解决这个问题。
AFL采用了forkserver方法,该方法为已加载的程序创建相同的克隆,并在每次运行时重复使用该克隆。 AFL还提供了持久模式和并行模式,持久模式有助于避免臭名昭著的execve()系统调用和链接过程的开销,并行模式有助于并行化在多核系统上的测试。此外,内核fuzzing中的因特尔的Processor Trace (PT)技术[11]减少了覆盖率追踪的开销。Xu Wen等人为了解决多核机器上并行fuzzing的性能瓶颈问题,设计并实现了3个新的操作原语[12],他们的实验表明这显著地提升了现代fuzzer的速度,包括AFL和LibFuzzer[13]。
5 面向各种应用的fuzzing
fuzzing被用来检测各种各样的应用程序,根据目标程序自身的特性,实践中存在许多不同的策略。本节总结了几种应用fuzzing技术的主要程序类型。
5.1 文件格式fuzzing
大部分应用程序需要进行文件处理。fuzzing可以对具有或不具有标准格式的文件进行操作。大多数关于fuzzing的研究集中在文件格式上,许多fuzzing工具被提出,例如PeachTech[14],AFL[1]及其扩展AFLFast[7]和AFLGo[8]。
文件格式fuzzing的一个重要分支是浏览器fuzzing。随着Web浏览器的发展,浏览器得到了扩展,比以往支持更多的功能。浏览器处理的文件已经从传统的HTML、CSS、JS文件扩展到其他类型的文件,例如pdf、svg,和其他浏览器扩展需要处理的文件格式。 浏览器将网页解析为DOM树,该树将网页解释为与事件和响应有关的文档对象树。 浏览器的DOM解析和页面渲染是当前特别热门的fuzzing对象。 针对Web浏览器的知名模糊工具包括Grinder框架[15],COMRaider[16],BF3[17]等。
5.2 内核fuzzing
面向操作系统内核的fuzzing始终是一个涉及许多挑战的棘手问题。与用户态fuzzing不同,首先,内核中的崩溃将导致整个系统瘫痪,如何捕获崩溃是一个难题。其次,fuzzer通常在ring 3下运行,系统权限机制导致了相对封闭的执行环境,如何与内核交互也是一个挑战。当前与内核通信的最佳方法是调用内核API函数。此外,诸如Windows内核和MacOS内核之类的流行操作系统内核是闭源的,并且很难以较低的性能开销进行检测。
通常通过调用具有随机生成的参数值的内核API函数来对OS内核进行测试。得益于智能fuzzing的发展,内核fuzzing也取得了一些新的进展。根据fuzzing的关注点,内核fuzzing可分为两类:基于知识的fuzzing和覆盖导向的fuzzing。 基于知识的fuzzer在fuzzing过程中会利用有关内核API函数的知识。使用内核API函数调用进行测试面临两个主要挑战:(1)API调用的参数应遵循API规范,保证正确的格式;(2)内核API调用的顺序应该是合法的。基于知识的fuzzing的代表性工作包括Trinity[18]和IMF[19]。 Trinity是参数类型已知的内核fuzzer,基于参数的类型生成测试用例。 syscall的参数根据数据类型进行修改。此外,某些枚举值和值的范围也需要是已知的,这些信息能帮助生成格式正确的测试用例。而IMF自己学习正确的API执行顺序以及API调用之间的值依赖性,并利用学到的知识来生成测试用例。
覆盖导向的fuzzing在用户态应用程序的应用上非常成功,研究者也开始在测试内核漏洞时应用基于覆盖导向的fuzzing方法。代表性的工作包括syzkaller[20],TriforceAFL[21]和kAFL[22]。 Syzkaller在一组QEMU虚拟机上运行内核,通过编译来对内核插桩,在fuzzing过程中会同时跟踪覆盖率和安全性违规情况。 TriforceAFL是AFL的修改版本,它支持用QEMU完整模拟的系统内核fuzzing。kAFL利用新的硬件功能Intel PT来跟踪覆盖率,仅跟踪内核代码。实验表明,kAFL比Triforce快40倍左右,大大提高了效率。
5.3 协议fuzzing
当前,许多本地应用程序以B/S模式被转换为网络服务。服务部署在网络上,客户端应用程序通过网络协议与服务器通信。如何对网络协议的安全性进行测试也是一个重要的问题。协议中的安全性问题可能导致比本地应用程序更严重的危害,例如拒绝服务,信息泄漏等。与文件格式fuzzing相比,协议fuzzing面临着不同的挑战。服务可以定义自己的通信协议,黑盒情况下难确定协议标准。即使协议具有标准的文档化定义,实际部署的时候也不一定严格遵循RFC等文档的规范。
代表性的协议fuzzer包括SPIKE,SPIKE提供了一组工具使用户可以快速进行网络协议的压力测试。 AutoFuzz[23]通过构造有限状态自动机来学习协议实现,并进一步利用所学的知识来生成测试用例。SNOOZE[24]使用有状态的fuzzing方法识别协议缺陷。De Ruiter和Pol提出了一种协议状态fuzzing方法[25],该方法记录状态机中的TLS工作状态,并根据逻辑流进行模糊测试。以前的研究通常采用有状态的方法来对协议的工作过程进行建模,并根据协议规范生成测试用例。
6 fuzzing的发展趋势
作为一种检测漏洞的自动化方法,fuzzing有效且高效,但也仍然面临着许多问题需要解决。
第一,更加智能化的fuzzing。智能fuzzing给测试效率的提升带来了更多可能性。通过各种各样的方法收集目标程序的执行信息,利用不同类型漏洞的特点,智能fuzzing对测试过程进行更详尽的控制,有助于找到更复杂的漏洞。
第二,新技术的引入。新技术可以从许多方面帮助改善漏洞。机器学习及其相关技术已经被用于fuzzing的测试用例生成阶段。如何将新技术的优点和特性与fuzzing结合,如何将fuzzing面临的主要挑战分割为新技术可以解决的问题,这也是值得考虑的问题。
第三,结合系统和硬件的研究。Vyukov和Schumilo证明了利用硬件特性可以极大地提升fuzzing的效率,新的系统特性和硬件特性不应该被忽视。
参考文献
[1] Zalewski, Michal. “American fuzzy lop.” URL: http://lcamtuf.coredump.cx/afl (2017).
[2] Rawat S, Jain V, Kumar A, et al. “VUzzer: Application-aware Evolutionary Fuzzing”, In Proc. of NDSS, pp. 17: 1-14, ISOC, 2017.
[3] Wang J, Chen B, Wei L, et al. “Skyfire: Data-driven seed generation for fuzzing”, In Proc. of S&P, pp. 579-594, IEEE, 2017.
[4] Godefroid P, Singh R, Peleg H. “Machine learning for input fuzzing”, U.S. Patent Application No. 15/638,938.
[5]: Rajpal M, Blum W, Singh R. “Not all bytes are equal: Neural byte sieve for fuzzing”, arXiv preprint arXiv:1711.04596, 2017.
[6]:Nichols N, Raugas M, Jasper R, et al. “Faster fuzzing: Reinitialization with deep neural models”, arXiv preprint arXiv:1711.02807, 2017.
[7] Böhme M, Pham V T, Roychoudhury A. “Coverage-based greybox fuzzing as markov chain”, IEEE Transactions on Software Engineering, 45(5): 489-506, 2017.
[8] Böhme M, Pham V T, Nguyen M D, et al. “Directed greybox fuzzing”, In Proc. of CCS, pp. 2329-2344, ACM, 2017.
[9] Wang S, Nam J, Tan L. “QTEP: quality-aware test case prioritization”, In Proc. of ESEC/SIGSOFT FSE, pp. 523-534, ACM, 2017.
[10] Petsios T, Zhao J, Keromytis A D, et al. “Slowfuzz: Automated domain-independent detection of algorithmic complexity vulnerabilities”, In Porc. of CCS, pp. 2155-2168, ACM, 2017.
[11] James R. “Processor tracing.” URL: https://software.intel.com/en-us/blogs/2013/09/18/processor-tracing (2017).
[12] Xu W, Kashyap S, Min C, et al. “Designing new operating primitives to improve fuzzing performance”, In Proc. of CCS, pp. 2313-2328, ACM, 2017.
[13] “A library for coverage-guided fuzz testing”. URL: https://llvm.org/docs/LibFuzzer.html (2017).
[14] “PeachTech”. URL: https://www.peach.tech/ (2017).
[15] Stephenfewer. “Grinder”. URL: https://github.com/stephenfewer/grinder.Accessed (2017).
[16] Zimmer D. “Comraider”. URL: http://sandsprite.com/tools.php?id=16 (2017).
[17] Aldeid. “Browser fuzzer 3”. URL: https://www.aldeid.com/wiki/Bf3 (2017).
[18] Jones D. “Trinity”. https://github.com/kernelslacker/trinity (2010).
[19] Han H S, Cha S K. “Imf: Inferred model-based fuzzer”, In Proc. of CCS, pp. 2345-2358, ACM, 2017.
[20] Vyukov D. “Syzkaller”. URL: https://github.com/google/syzkaller (2017).
[21] Hertz J. “Triforceafl”. URL: https://github.com/nccgroup/TriforceAFL (2017).
[22] Schumilo S, Aschermann C, Gawlik R, et al. “kAFL: Hardware-Assisted Feedback Fuzzing for {OS} Kernels”, In Proc. of USENIX Security, pp. 167-182, USENIX Association, 2017.
[23] Gorbunov S, Rosenbloom A. “Autofuzz: Automated network protocol fuzzing framework”, IJCSNS, 10(8): 239, 2010.
[24] Banks G, Cova M, Felmetsger V, et al. "SNOOZE: toward a Stateful NetwOrk prOtocol fuzZEr, In Proc. of ISC, pp. 343-358, Springer, 2006.
[25] De Ruiter J, Poll E. “Protocol State Fuzzing of {TLS} Implementations”, In Proc. of USENIX Security, pp. 193-206, USENIX Association, 2015.